 "
]
},
{
"cell_type": "markdown",
"id": "e60bbdfc-6e2c-4275-ba3e-d72e70ab021b",
"metadata": {
"tags": []
},
"source": [
"# Enhancing Data Science Outcomes With Efficient Workflow #"
]
},
{
"cell_type": "markdown",
"id": "b9e9d7e6-8b43-45f0-9de5-9889a67a229b",
"metadata": {},
"source": [
"## 04 - NVTabular ##\n",
"In this lab, you will learn the motivation behind doing data science on a GPU cluster. This lab covers the ETL, data exploration, and feature engineering steps of the data processing pipeline. Extract, transform, load, or [ETL](https://en.wikipedia.org/wiki/Extract,_transform,_load), is the process where data is transformed into a proper structure for the purposes of querying and analysis. Feature engineering, on the other hand, involves the extraction and transformation of raw data. \n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"id": "e60bbdfc-6e2c-4275-ba3e-d72e70ab021b",
"metadata": {
"tags": []
},
"source": [
"# Enhancing Data Science Outcomes With Efficient Workflow #"
]
},
{
"cell_type": "markdown",
"id": "b9e9d7e6-8b43-45f0-9de5-9889a67a229b",
"metadata": {},
"source": [
"## 04 - NVTabular ##\n",
"In this lab, you will learn the motivation behind doing data science on a GPU cluster. This lab covers the ETL, data exploration, and feature engineering steps of the data processing pipeline. Extract, transform, load, or [ETL](https://en.wikipedia.org/wiki/Extract,_transform,_load), is the process where data is transformed into a proper structure for the purposes of querying and analysis. Feature engineering, on the other hand, involves the extraction and transformation of raw data. \n",
"\n",
"
| \n", " | event_time | \n", "event_type | \n", "product_id | \n", "category_id | \n", "category_code | \n", "brand | \n", "price | \n", "user_id | \n", "user_session | \n", "session_product | \n", "... | \n", "cat_1 | \n", "cat_2 | \n", "cat_3 | \n", "date | \n", "ts_hour | \n", "ts_minute | \n", "ts_weekday | \n", "ts_day | \n", "ts_month | \n", "ts_year | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "2020-03-01 04:54:09 | \n", "purchase | \n", "10301400 | \n", "2232732104888681081 | \n", "apparel.scarf | \n", "bburago | \n", "19.280001 | \n", "537144080 | \n", "053d5ad3-01c7-4dfb-9079-e121c33b0938 | \n", "053d5ad3-01c7-4dfb-9079-e121c33b0938_10301400 | \n", "... | \n", "scarf | \n", "NA | \n", "NA | \n", "2020-03-01 | \n", "4 | \n", "54 | \n", "6 | \n", "1 | \n", "3 | \n", "2020 | \n", "
| 1 | \n", "2020-03-01 04:55:26 | \n", "purchase | \n", "15700285 | \n", "2232732094134485388 | \n", "UNKNOWN | \n", "UNKNOWN | \n", "154.190002 | \n", "514686549 | \n", "3c842e53-1e47-4941-83e0-2a27a8fdeaf1 | \n", "3c842e53-1e47-4941-83e0-2a27a8fdeaf1_15700285 | \n", "... | \n", "NA | \n", "NA | \n", "NA | \n", "2020-03-01 | \n", "4 | \n", "55 | \n", "6 | \n", "1 | \n", "3 | \n", "2020 | \n", "
| 2 | \n", "2020-03-01 04:54:46 | \n", "purchase | \n", "21406331 | \n", "2232732082063278200 | \n", "electronics.clocks | \n", "casio | \n", "30.369999 | \n", "522564661 | \n", "cfa89b7f-5b34-4d65-a135-bb924d98af9c | \n", "cfa89b7f-5b34-4d65-a135-bb924d98af9c_21406331 | \n", "... | \n", "clocks | \n", "NA | \n", "NA | \n", "2020-03-01 | \n", "4 | \n", "54 | \n", "6 | \n", "1 | \n", "3 | \n", "2020 | \n", "
| 3 | \n", "2020-03-01 07:45:47 | \n", "purchase | \n", "1004665 | \n", "2232732093077520756 | \n", "construction.tools.light | \n", "samsung | \n", "816.690002 | \n", "596178054 | \n", "f84b2b78-50a0-4e34-ad8d-da60a6178091 | \n", "f84b2b78-50a0-4e34-ad8d-da60a6178091_1004665 | \n", "... | \n", "tools | \n", "light | \n", "NA | \n", "2020-03-01 | \n", "7 | \n", "45 | \n", "6 | \n", "1 | \n", "3 | \n", "2020 | \n", "
| 4 | \n", "2020-03-02 05:26:04 | \n", "purchase | \n", "21400996 | \n", "2232732082063278200 | \n", "electronics.clocks | \n", "casio | \n", "81.159996 | \n", "537131991 | \n", "b19b380b-2db7-4c6e-bb91-998556315d0a | \n", "b19b380b-2db7-4c6e-bb91-998556315d0a_21400996 | \n", "... | \n", "clocks | \n", "NA | \n", "NA | \n", "2020-03-02 | \n", "5 | \n", "26 | \n", "0 | \n", "2 | \n", "3 | \n", "2020 | \n", "
5 rows × 22 columns
\n", "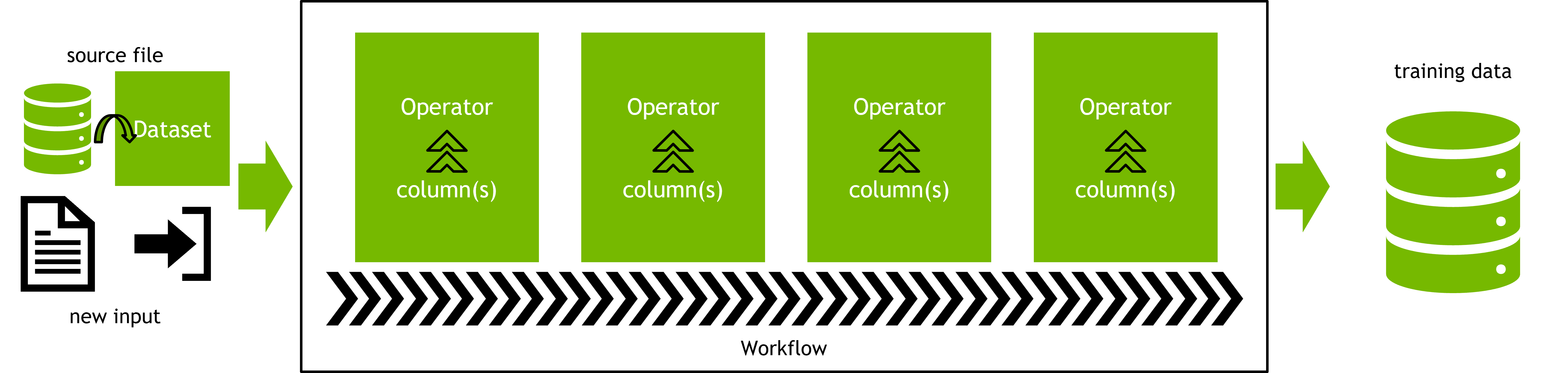

| \n", " | brand | \n", "cat_0 | \n", "cat_1 | \n", "cat_2 | \n", "cat_3 | \n", "ts_hour | \n", "ts_minute | \n", "ts_weekday | \n", "brand_target_sum | \n", "brand_count | \n", "... | \n", "cat_3_count | \n", "TE_brand_target | \n", "TE_cat_0_target | \n", "TE_cat_1_target | \n", "TE_cat_2_target | \n", "TE_cat_3_target | \n", "price | \n", "relative_price_product | \n", "relative_price_category | \n", "target | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "952 | \n", "6 | \n", "19 | \n", "4 | \n", "3 | \n", "4 | \n", "54 | \n", "6 | \n", "12 | \n", "71 | \n", "... | \n", "2460405 | \n", "0.220351 | \n", "0.349630 | \n", "0.262990 | \n", "0.340122 | \n", "0.410012 | \n", "-1.583984 | \n", "0.000000 | \n", "-0.678853 | \n", "1 | \n", "
| 1 | \n", "5 | \n", "5 | \n", "4 | \n", "4 | \n", "3 | \n", "4 | \n", "55 | \n", "6 | \n", "81333 | \n", "234973 | \n", "... | \n", "2460405 | \n", "0.346285 | \n", "0.297294 | \n", "0.297294 | \n", "0.339305 | \n", "0.410121 | \n", "0.031592 | \n", "-0.034146 | \n", "0.261951 | \n", "1 | \n", "
| 2 | \n", "34 | \n", "7 | \n", "10 | \n", "4 | \n", "3 | \n", "4 | \n", "54 | \n", "6 | \n", "3259 | \n", "8325 | \n", "... | \n", "2460405 | \n", "0.387353 | \n", "0.402070 | \n", "0.429762 | \n", "0.340703 | \n", "0.410679 | \n", "-1.237676 | \n", "0.000000 | \n", "-0.883515 | \n", "1 | \n", "
| 3 | \n", "3 | \n", "3 | \n", "3 | \n", "3 | \n", "3 | \n", "7 | \n", "45 | \n", "6 | \n", "226354 | \n", "457906 | \n", "... | \n", "2460405 | \n", "0.494355 | \n", "0.483119 | \n", "0.482531 | \n", "0.488641 | \n", "0.410679 | \n", "1.350904 | \n", "-0.017399 | \n", "0.772717 | \n", "1 | \n", "
| 4 | \n", "34 | \n", "7 | \n", "10 | \n", "4 | \n", "3 | \n", "5 | \n", "26 | \n", "0 | \n", "3259 | \n", "8325 | \n", "... | \n", "2460405 | \n", "0.396942 | \n", "0.401396 | \n", "0.427910 | \n", "0.339305 | \n", "0.410121 | \n", "-0.473307 | \n", "-0.006232 | \n", "-0.688708 | \n", "1 | \n", "
5 rows × 27 columns
\n", "| \n", " | brand | \n", "cat_0 | \n", "cat_1 | \n", "cat_2 | \n", "cat_3 | \n", "ts_hour | \n", "ts_minute | \n", "ts_weekday | \n", "brand_target_sum | \n", "brand_count | \n", "... | \n", "cat_3_count | \n", "TE_brand_target | \n", "TE_cat_0_target | \n", "TE_cat_1_target | \n", "TE_cat_2_target | \n", "TE_cat_3_target | \n", "price | \n", "relative_price_product | \n", "relative_price_category | \n", "target | \n", "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", "952 | \n", "6 | \n", "19 | \n", "4 | \n", "3 | \n", "4 | \n", "54 | \n", "6 | \n", "12 | \n", "71 | \n", "... | \n", "2460405 | \n", "0.220351 | \n", "0.349630 | \n", "0.262990 | \n", "0.340122 | \n", "0.410012 | \n", "-1.583984 | \n", "0.000000 | \n", "-0.678853 | \n", "1 | \n", "
| 1 | \n", "5 | \n", "5 | \n", "4 | \n", "4 | \n", "3 | \n", "4 | \n", "55 | \n", "6 | \n", "81333 | \n", "234973 | \n", "... | \n", "2460405 | \n", "0.346285 | \n", "0.297294 | \n", "0.297294 | \n", "0.339305 | \n", "0.410121 | \n", "0.031592 | \n", "-0.034146 | \n", "0.261951 | \n", "1 | \n", "
| 2 | \n", "34 | \n", "7 | \n", "10 | \n", "4 | \n", "3 | \n", "4 | \n", "54 | \n", "6 | \n", "3259 | \n", "8325 | \n", "... | \n", "2460405 | \n", "0.387353 | \n", "0.402070 | \n", "0.429762 | \n", "0.340703 | \n", "0.410679 | \n", "-1.237676 | \n", "0.000000 | \n", "-0.883515 | \n", "1 | \n", "
| 3 | \n", "3 | \n", "3 | \n", "3 | \n", "3 | \n", "3 | \n", "7 | \n", "45 | \n", "6 | \n", "226354 | \n", "457906 | \n", "... | \n", "2460405 | \n", "0.494355 | \n", "0.483119 | \n", "0.482531 | \n", "0.488641 | \n", "0.410679 | \n", "1.350904 | \n", "-0.017399 | \n", "0.772717 | \n", "1 | \n", "
| 4 | \n", "34 | \n", "7 | \n", "10 | \n", "4 | \n", "3 | \n", "5 | \n", "26 | \n", "0 | \n", "3259 | \n", "8325 | \n", "... | \n", "2460405 | \n", "0.396942 | \n", "0.401396 | \n", "0.427910 | \n", "0.339305 | \n", "0.410121 | \n", "-0.473307 | \n", "-0.006232 | \n", "-0.688708 | \n", "1 | \n", "
5 rows × 27 columns
\n", " "
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.16"
}
},
"nbformat": 4,
"nbformat_minor": 5
}